
Nếu muốn các ứng dụng trở nên thông minh hơn thì phải cần tới phương thức xử lí dữ liệu nhanh hơn (Fast data). Tuy nhiên, hệ thống cơ sở dữ liệu truyền thống lại quá chậm chạp trong khi nhu cầu phân tích xử lí dữ liệu đòi hỏi thời đáp ứng thời gian thực.
Một xu hướng đang nổi lên là sử dụng công cụ mã nguồn mở trong doanh nghiệp nhằm xử lí luồng dữ liệu với các truy vấn phức tạp và tăng cường khả năng giao dịch. Một khái niệm mới về dữ liệu được nhắc đến khá nhiều trong năm 2014, đó là NewSQL, được xem là nền tảng của Fast Data. NewSQL là hệ quản trị CSDL với hiệu năng mở rộng và tốc độ cao nhằm giải quyết các vấn đề về xử lí giao dịch trực tuyến (Online transaction processing) của hệ quản trị cơ sở dữ liệu SQL truyền thống.
Công cụ mã nguồn mở
Cách đây gần 10 năm, việc phân tích dòng dữ liệu lên đến petabyte là một điều không tưởng đối với các thiết bị phần cứng. Những công cụ mã nguồn mở như Apache Hadoop cung cấp một nền tảng phân tán mạnh để lưu trữ và quản lí dữ liệu lớn. Nền tảng này chạy ứng dụng trên các cụm phần cứng lớn, xử lí khối dữ liệu lên đến petabyte trên hàng ngàn hệ thống quản lí dữ liệu phân tán và hệ thống ảo hóa. Điều này làm giảm chi phí và tăng cường sức mạnh bảo mật cho doanh nghiệp, từ đó lĩnh vực Dữ liệu lớn (Big data) ra đời.
Một cuộc cách mạng tương tự đang xảy ra với tên gọi là Dữ liệu nhanh (Fast data). Big Data thường được tạo ra bởi các luồng dữ liệu khổng lồ với tốc độ sản sinh đáng kinh ngạc, ví dụ như dữ liệu về việc nhấp chuột theo thời gian thực, thông tin về tài chính hay dữ liệu của các cảm biến. Thường thì những điều này diễn ra hàng ngàn đến hàng chục ngàn lần mỗi giây. Kiểu dữ liệu này được giới chuyên gia đặt cái tên là "vòi rồng".
Khi nói về vòi rồng trong dữ liệu lớn, chúng ta không đo khối lượng kiểu như gigabyte điển hình mà là bằng lượng dữ liệu MB trên mỗi giây hay terabyte mỗi ngày. Chúng ta đang nói về tốc độ cũng như khối lượng và đó là điểm cốt lõi lõi của sự khác biệt giữa dữ liệu lớn và kho dữ liệu. Big Data không chỉ lớn mà còn có tốc độ xử lí cao.
Những lợi ích của Big Data sẽ không còn nếu nó không mới và nhanh chóng di chuyển từ các "vòi rồng" đến các nền tảng kiểu như Hadoop Distributed File System (hệ thống lưu trữ chính của công cụ Hadoop) hay công cụ phân tích hệ quản lí cơ sở dữ liệu quan hệ (RDBMS) hoặc thậm chí là các tập tin dữ liệu thông thường. Những đặc tính đại diện cho xu hướng dữ liệu mới này phải là luôn đáp ứng, luôn trong tình trạng sẵn sàng và có khả năng xử lí xử lí theo lô (batch processing).
Công nghệ về dữ liệu mới phải phù hợp với môi trường xung quanh mới được xem là có giá trị. Hoạt động dữ liệu không quá tốn kém và phù hợp với các dòng sản phẩm phần cứng phổ biến. Cũng giống như giá trị của dữ liệu lớn - Big Data, giá trị trong dữ liệu nhanh - Fast Data được xem là những kì vọng của tương lai về mô hình hàng đợi thông điệp (message) và hệ thống truyền tải như Apache Kafka hay Apache Storm.
Từ những nhu cầu về cơ sở dữ liệu tương lai đó nên đã có sự ra đời NoSQL năm 1998 trước đây và hiện nay là NewSQL.
Giá trị Fast Data
Cách tốt nhất để nắm bắt được giá trị của dữ liệu đầu vào là việc phương thức xử lí khi thông tin được truyền đến. Giá trị của dữ liệu đó được thể hiện ở việc tiết kiệm thời gian xử lí mà không có tác động của con người.
Để xử lí dữ liệu khi đến hàng chục ngàn đến hàng triệu sự kiện mỗi giây, bạn sẽ cần hai công nghệ: Đầu tiên, hệ thống truyền tải có khả năng cung cấp các sự kiện nhanh ở nguồn vào; và thứ hai là hệ thống lưu trữ có khả năng xử lí nhanh mỗi khi dữ liệu được truyền đến.
Nguồn cung của Fast Data
Hai hệ thống trực tuyến phổ biến đã nổi lên trong vài năm qua: Apache Storm và Apache Kafka. Được phát triển bởi đội ngũ kĩ sư tại Twitter. Storm đáng tin cậy trong việc xử lí dòng dữ liệu vô tận ở mức hàng triệu tin đến mỗi giây. Kafka, được phát triển bởi đội ngũ kĩ sư tại LinkedIn, đây là một hệ thống hàng đợi thông điệp phân bố với hiệu suất cao. Cả hai hệ thống truyền này giải quyết đáp ứng được nhu cầu xử lí dữ liệu nhanh.
Một điểm khác biệt là Kafka được thiết kế để có một hàng đợi thông điệp và giải quyết các vấn đề về các hiện trạng công nghệ hiện có. Đó là loại một dạng hàng đợi cao cấp với khả năng mở rộng không giới hạn, sử dụng mô hình hạ tầng chia sẻ... Một tổ chức có thể triển khai một cụm Kafka để đáp ứng tất cả các nhu cầu truyền tin của mình theo hàng đợi
Xử lí với Fast Data
Truyền tin chỉ là một phần của giải phápmà cơ sở dữ liệu quan hệ truyền thống có xu hướng giới hạn hiệu suất. Một số có thể lưu trữ dữ liệu với tốc độ cao, nhưng tốc độ sẽ giảm khi chúng phải thực hiện thêm các thao tác như xác minh, bổ sung trước khi được chuyển đổi. NoSQL thích hợp cho các mô hình lưu trữ dữ liệu có tính đặc thù như object oriented, document oriented, xml database,…
Tuy nhiên, nếu bạn đang thực hiện các truy vấn phức tạp và các hoạt động kiểm soát quá trình trao đổi thông tin giữa một cơ sở dữ liệu với một phương tiện của người truy cập thì giải pháp NewSQL có thể đáp ứng được hiệu suất cũng như độ phức tạp giao dịch.
NoSQL có nghĩa là Non-Relational - không ràng buộc. Tuy nhiên hiện nay người ta thường hiểu là NoSQL là Not Only SQL - Không chỉ SQL. Đây là thuật ngữ chung cho các hệ CSDL không sử dụng mô hình dữ liệu quan hệ. NoSQL đặc biệt nhấn mạnh đến mô hình lưu trữ cặp giá trị - khóa và hệ thống lưu trữ phân tán. NoSQL đặc biệt thích hợp cho các ứng dụng rất lớn (dịch vụ tìm kiếm, mạng xã hội ,…). Với những ứng dụng vừa và lớn thì RDBMs vẫn thích hợp hơn.
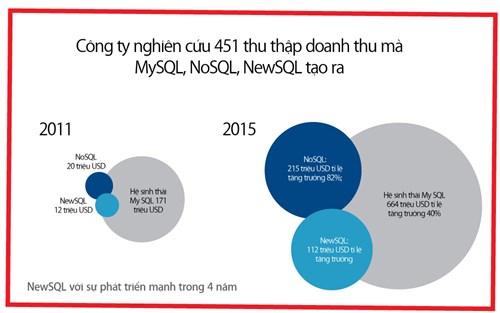
NewSQL nhằm mô tả hệ thống có khả năng mở rộng của NoSQL, trong khi vẫn cung cấp các đặc tính ACID (tính toàn vẹn của cơ sở dữ liệu) đảm bảo quan hệ dữ liệu thông thường. NewSQL đang được sử dụng khá nhiều ở các công ty lớn trên thế giới và thuật ngữ được gọi lần đầu tiên bởi tổ chức the 451 Group vào năm 2011.
Theo PC World VN.
Bình luận